こんばんはエンジニアの眠れない夜です。
人工知能(AI)技術の進歩により、多くの企業がカスタマーサポートの効率化を目指しています。その中で、ChatGPTのような大規模言語モデルのファインチューニングに興味がり試してみました。今回は、実際にChatGPTをファインチューニングした経験と、その結果について共有します。
ファインチューニングの概要
今回のプロジェクトでは、以下の手順でChatGPTのファインチューニングを行いました:
- 教師データとして1200件のカスタマーサポートメール履歴を用意
- システムプロンプト、問い合わせ、回答の3要素を含むデータセットを作成
- 問い合わせに対して適切な回答を生成するモデルを目指す
- 学習時間は約1時間半
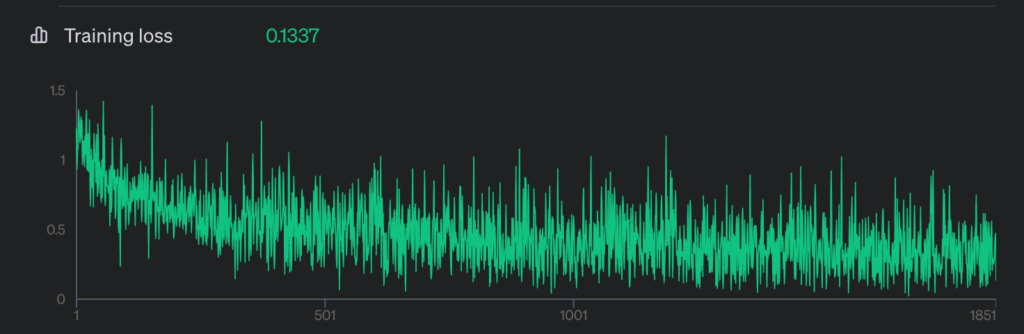
Training loss は 0.1337 でした。これが良いのか悪いのか判断する指標を持ち合わせていません。
検証プロセス
ファインチューニング後のモデルの性能を評価するため、以下の検証を行いました:
- 教師データに含まれていない新しい問い合わせを入力
- 教師データに含まれる問い合わせで確認
結果と考察
1. 新しい問い合わせに対する応答
残念ながら、モデルは教師データに含まれていない問い合わせに対して適切な知識の獲得ができていませんでした。さらに、出力が途中で途切れてしまうという問題も発生しました。
2. 既知の問い合わせに対する応答
教師データに含まれる問い合わせに対しては、部分的に知識を獲得しているように見える箇所がありました。しかし、全体的な性能はファインチューニングを行っていないChatGPT 3.5 Turboモデルの方が優れているという結果になりました。
今後の課題と展望
今回の結果から、1200件程度の教師データではカスタマーサポートの知識を十分に獲得し、正確な回答を生成するのは難しいことが分かりました。今後の改善策として、以下の点に注目していきます:
- 教師データの質と量の見直し
- データの前処理方法の改善
- ファインチューニングのハイパーパラメータの調整
- より大規模なモデルの使用検討
まとめ
ChatGPTのファインチューニングは、カスタマーサポートの自動化に大きな可能性を秘めています。しかし、今回の経験から、効果的なファインチューニングには十分な量が不足しているのかも知れません。
より効果的なAIカスタマーサポートシステムの構築を目指して教師データに問題がないかを確認し、再度学習させてみようと思います。
この分野に興味のある方々にとって、本記事が何らかの参考になれば幸いです。
コメントを残す