
こんばんはエンジニアの眠れない夜です。
前回はkeras−yolo3の使い方をご紹介しました。
まだ読んでいない方は先にkeras-yolo3の使い方を読んでkeras-yolo3を動くようにしてからこの先を読み進めるとスムーズにkeras-yolo3の学習を始められます。
物体検出ってこんなに簡単にできるの!?ってなります。機械学習がとっても身近なものに感じられるようになります。
keras−yolo3の独自データセット学習の流れ
- sleepless-se/keras-yolo3 をクローン
- 教師画像をダウンロード
- 教師画像をリサイズ
- VOTTでアノテーションを作成
- アノテーションファイルをYOLO用に変換
- YOLO学習開始
結構ステップが多くて大変そう(;´Д`)
と、感じますがそこはディープラーニング、仕方ないですね(^_^;)
sleepless-se/keras-yolo3をクローン
keras−yolo3の学習が行いやすいようにオリジナルのkeras-yolo3に手を加えたものを公開しました。
こちらからクローンしてください。
git clone https://github.com/sleepless-se/keras-yolo3.git keras-yolo3-sample
cd keras-yolo3-sampleクローンできたらrequirements.txtから必要なモジュールをインストールします。
cd pip install -r requirements.txtKeras 2.1.5 tensorflow 1.6.0がインストールされます。
※ テスト環境はPython 3.5.2です。なにかエラーが出る場合はバージョンを揃えたほうがいいです。私の環境ではPython 3.6.9で動作しました。
教師画像をダウンロード
物体検出をしたい画像を集める必要があります。
分量は各ラベル(対象)ごとに500は必要。1000枚くらいあるといいと書いている記事が多いです。
たくさん画像を集めてくるのは大変ですが、機械学習の画像収集ならiCrawlerを使うと1回の実行で100枚の画像を集められるので楽ができます。
今回はお試しなので、各クラス(ラベル)ごとに20枚程度で大丈夫です。
あまりたくさんあると大変です。そして動かなかった時に涙します。
精度は出ませんが、今回は学習ができるかを確認することが目的です。
教師画像をリサイズ
一通り画像のダウンロードができたらkeras-yolo3のimages直下に画像を全て移動させます。
keras-yolo3ディレクトリで下記のコードを実行します。
python resize_images.pyこのコードを実行するとimagesに保存されている画像ファイルのアスペクト比を維持しながら 320px × 320px の画像にリサイズします。画像が正方形ではない場合は白で背景が塗り足されます。
※ このコードは私が追加したものなのでオリジナルのkeras-yolo3には入っていないので気をつけてください。
教師画像のサイズは32pxの倍数である必要があるので320pxに設定しています。32の倍数であれば128pxや352pxなどでも大丈夫です。
あまり画像が大きすぎると学習時にメモリに乗り切らずクラッシュするため小さめのサイズが無難です。
リサイズ時の大きさを変更したい場合は第一引数でサイズを指定してください。
python resize_images.py 128
また、今回はデフォルトでimagesフォルダの画像をリサイズしてresize_imageに保存されるようになっていますが33行目辺りで設定可能です。
images_dir = 'images/' # 適宜変更
image_save_dir = 'resize_image/' # 適宜変更
PNGファイルの場合UserWarning: Palette images with Transparency expressed in bytes should be converted to RGBA images ' expressed in bytes should be converted ' +と警告が出ることがありますが無視して大丈夫です。
アノテーションツールVOTT
画像のここに対象物がありますよ。と伝えることをアノテーションといいます。
このアノテーションを作成するアプリはたくさんあるのですが、個人的にはVOTTというアプリケーションがおすすめです。
理由は
- Windows・Mac・Linuxで使える
- 書き出せるアノテーションファイルの形式が豊富
- 事前に学習したモデルに予測をさせてアノテーションができる
VoTTの使い方は別の記事にまとめたのでこちらをご覧ください。
※ アノテーションファイルを書き出すときのフォーマットはPascal VOCを使います。
アノテーションファイルをYOLOv3形式にあわせる
上記の記事を参考にPascal VOCでアノテーションファイルを書き出すと、resize_imageの中にxxx-PascalVOC-exportというフォルダが作成されます。
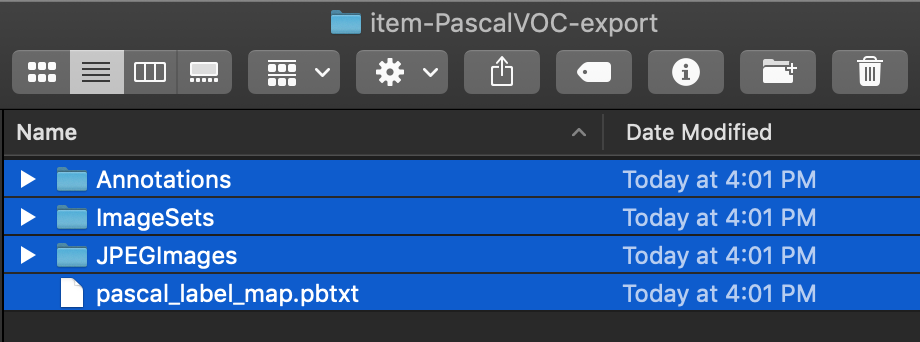
この中のフォルダとファイルをkeras-yolo3/VOCDevkit/VOC2007に移動させます。
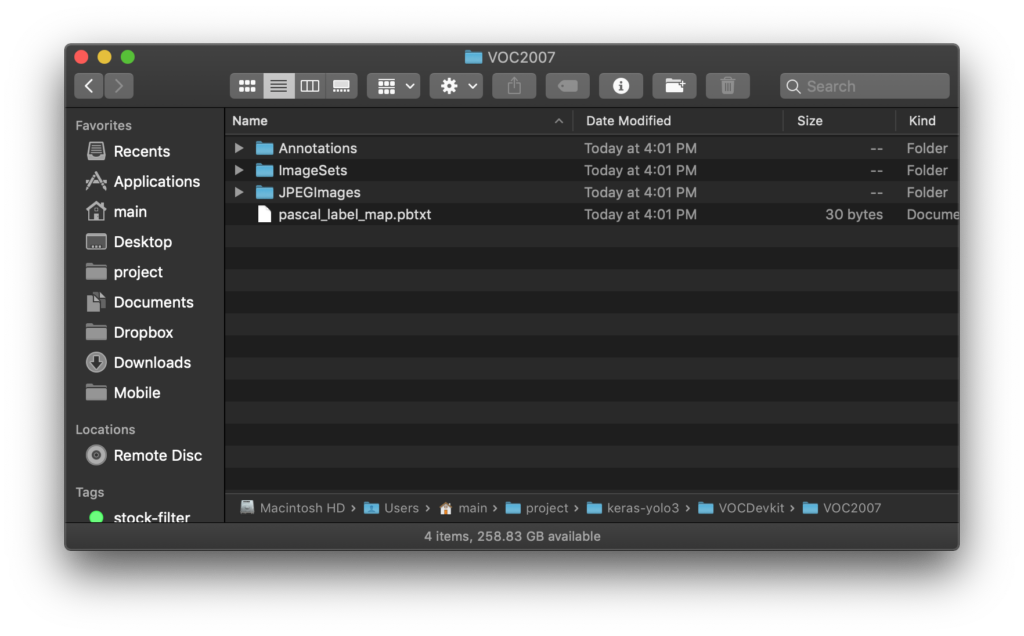
※ ここで移動しているのは書き出されたファイルとフォルダだけなのでアノテーションを設定した元のファイルは影響を受けないというVOTTの親切設計です。
train.txt、test.txt、val.txt を作成
学習を実行するにはtrain.txt、test.txt、val.txtの3つのファイルが必要です。
下記のコマンドを実行すると3つのファイルが作成されます。
python make_train_files.pyこのスクリプトは
書き出された学習用のアノテーションファイルをそれぞれ、train.txtとval.txtにまとめて
val.txtの中身をシャッフルして、3割ほどtest.txtに移動させて保存しています。
※ sleepless-se/keras-yolo3で追加したファイルです。オリジナルのkeras-yolo3にはありません。
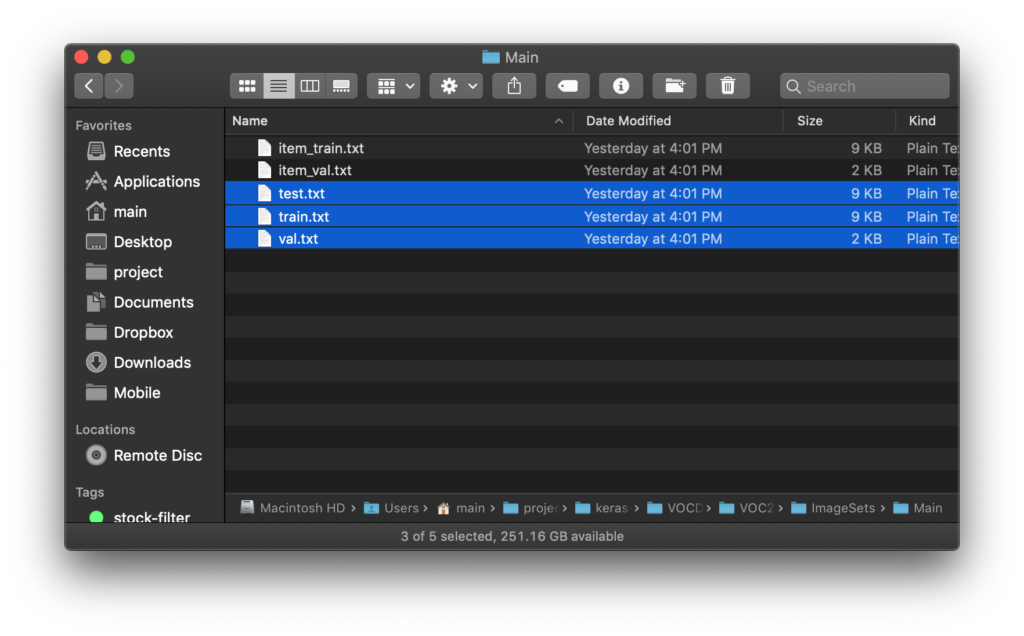
作成されたファイルはkeras-yolo3/VOCDevkit/VOC2007/ImageSets/Mainから確認できます。
- `ラベル名_train.txt`
- `ラベル名_val.txt`
というファイルがVoTTによって作成されたファイルです。
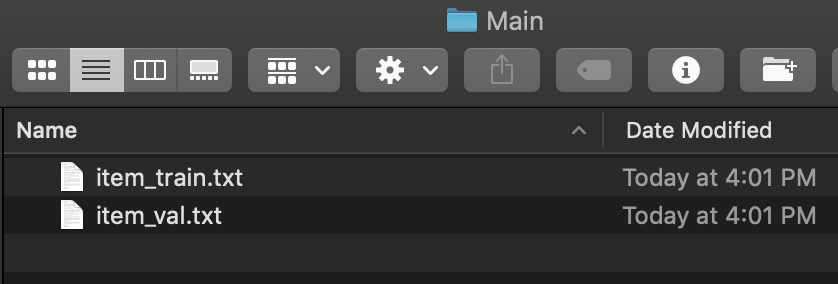
画像ではラベルをitemだけだったので _train _val は1つずつしか作成されていません。
複数ラベル設定した場合はラベルの数だけ作成されます。
スクリプトを実行して作成されたのがこちらの3つのファイルです。
val.txtとtest.txtに分ける理由が気になる方はこちらが参考になります。
YOLOの学習用に変換
VOTTで書き出したアノテーションはそのままではYOLOの学習には使えないのでvoc_annotation.pyでYOLOの学習用に変換します。
keras-yolo3直下にあるvoc_annotation.pyの6行目あたりのclassesのリストも自分で学習させる内容に合わせて修正します。
今回は1クラス(ラベル)なので
classes = ["item"]としました。適宜自分のクラス(ラベル)に合わせて設定してください。
python voc_annotation.pyでYOLOの学習用に変換されます。
※ ファイルの編集をしなくてもこちらも引数でクラスを指定できるようにしました。複数入力可能です。下記の例ではitemのみを追加しています。
python voc_annotation.py item
※ sleepless-se/keras-yolo3ではVOTT→YOLO v3の変換を行うようにオリジナルの voc_annotation.pyに変更を加えています。
変換されたファイルはkeras-yolo3直下にあるmodel_dataに保存されます。
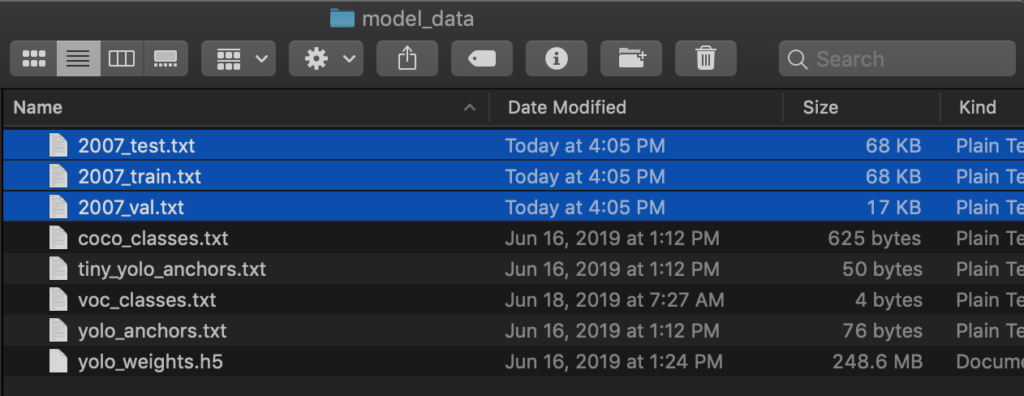
YOLO学習開始
models_dataの中にあるvoc_classes.txtにクラス(ラベル)を列挙する必要があるのですが、これも先程のvoc_annotation.pyで自動で作成するようにしています。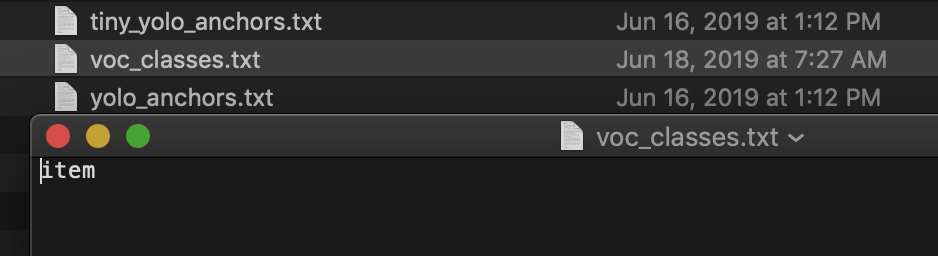 初期値はデフォルトのモデルで使われているクラスが列挙されています。
初期値はデフォルトのモデルで使われているクラスが列挙されています。
今回はitemだけなので上記の画像のようになります。
train.pyの編集
画像のサイズを320pxで進めてきましたが、他のサイズに変換している方は25行目辺りの下記のコードを修正してください。
input_shape = (320,320) # multiple of 32, hw
もしくは、第1引数でサイズを渡してください。
先ほど作成した学習用データとクラス名の設定はannotation_pathとclasses_pathで読み込んでいます。
def _main():
annotation_path = 'model_data/2007_train.txt'
log_dir = 'logs/000/'
classes_path = 'model_data/voc_classes.txt'学習用にweights(重み)を変換
YOLOv3のweightsをダウンロードしてきて、変換します。
※ weightsの変換が必要なのはもとのYOLOのweightsがKeras用ではないからだと思います。
wget https://pjreddie.com/media/files/yolov3.weights
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5未確認ですがこのページにある他のweightsを使えばベースとなるモデルを変えて移転学習ができると思います。 ※今回はYOLOv3-608を使用しています。
YOLO 学習開始!
変換ができたらここまでずいぶん長い道のりでしたがいよいよ学習開始です!
下記のコマンドを実行すると学習が始まります。
python train.py※ 画像のサイズを指定する場合はこのようにします。
python train.py 128
初めの1分ほどでエラーが出なければ設定に問題はありません。
これまでの作業で設定を間違えているとエラーが出ます。
※ 私はここで数時間、四苦八苦しました(;´Д`)
教師データの量とスペックによりますが、CPU環境で問題なければ1日くらい待てば学習が終了します。
壊滅的な遅さですね(゜o゜;
メモリ不足だと学習の途中で落ちます。私は12時間学習させたところで落ちたことがあります…( TДT) MacBook Pro メモリ16GB
train.pyの57行目辺りのバッチサイズを32以下の2の倍数にすると一度に消費するメモリが少なくなるので落ちなくなります。
batch_size = 32※ 他のブログを読んでいると8に設定してうまくいっている人が多いようです。
バッチサイズは第二引数で指定できるようにしています。
python train.py 320 8
KeyError: ‘val_loss’が出た時は?
Epoch 1/50
1/1 [==============================] - 4s 4s/step - loss: 1133.3969
Epoch 2/50
1/1 [==============================] - 2s 2s/step - loss: 1034.1313
Epoch 3/50
1/1 [==============================] - 2s 2s/step - loss: 934.3787
Traceback (most recent call last):
File "train.py", line 195, in
_main()
File "train.py", line 70, in _main
callbacks=[logging, checkpoint])
File "/Users/main/.pyenv/versions/3.7.3/lib/python3.7/site-packages/keras/legacy/interfaces.py", line 91, in wrapper
return func(*args, **kwargs)
File "/Users/main/.pyenv/versions/3.7.3/lib/python3.7/site-packages/keras/engine/training.py", line 1418, in fit_generator
initial_epoch=initial_epoch)
File "/Users/main/.pyenv/versions/3.7.3/lib/python3.7/site-packages/keras/engine/training_generator.py", line 251, in fit_generator
callbacks.on_epoch_end(epoch, epoch_logs)
File "/Users/main/.pyenv/versions/3.7.3/lib/python3.7/site-packages/keras/callbacks.py", line 79, in on_epoch_end
callback.on_epoch_end(epoch, logs)
File "/Users/main/.pyenv/versions/3.7.3/lib/python3.7/site-packages/keras/callbacks.py", line 429, in on_epoch_end
filepath = self.filepath.format(epoch=epoch + 1, **logs)
KeyError: 'val_loss'
KeyError:'val_loss'とエラーが出た時はkeras-yolo3/model_data/2007_test.txtのテストファイルに含まれるファイル(行)が10個以下の場合です。
動作確認のために動かすだけなら2007_test.txt内の行をコピペで10行に増やすだけで大丈夫です。
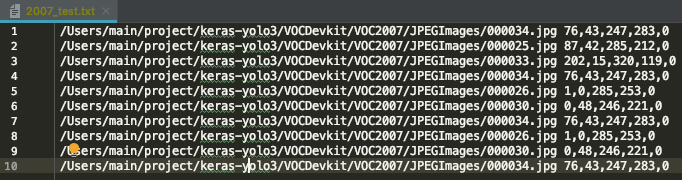
学習結果に影響が出るので本番ではこういうことは絶対にしてはいけませんが、本番の場合はテスト用のデータが10件に満たないということはそもそも無いのでこういったエラーは出ません。
学習済みのモデルを実行
学習済みのモデルはkeras-yolo3/logs/000/に保存されいるtrained_weights_final.h5を使います。
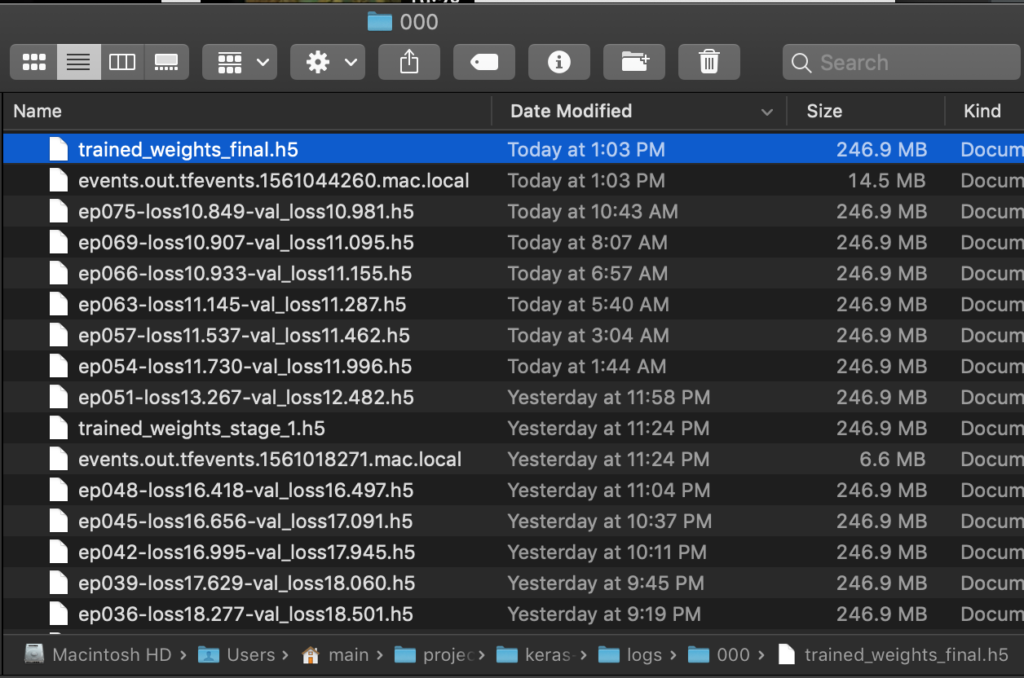
※ 学習中にベストスコアが出たタイミングでもep075-loss10.849-val_loss10.981.h5等のファイル名で保存されています。
sleepless-se/keras-yolo3ではすぐに学習済みのモデルが使えるようにyolo.pyの24行目辺りのmodel_pathを下記のように変更しています。
"model_path": 'logs/000/trained_weights_final.h5',
画像のサイズを変更している人は29行目辺りの画像のサイズ設定を行います。
"model_image_size" : (320, 320),後は画像や動画を入れて実行するだけです。
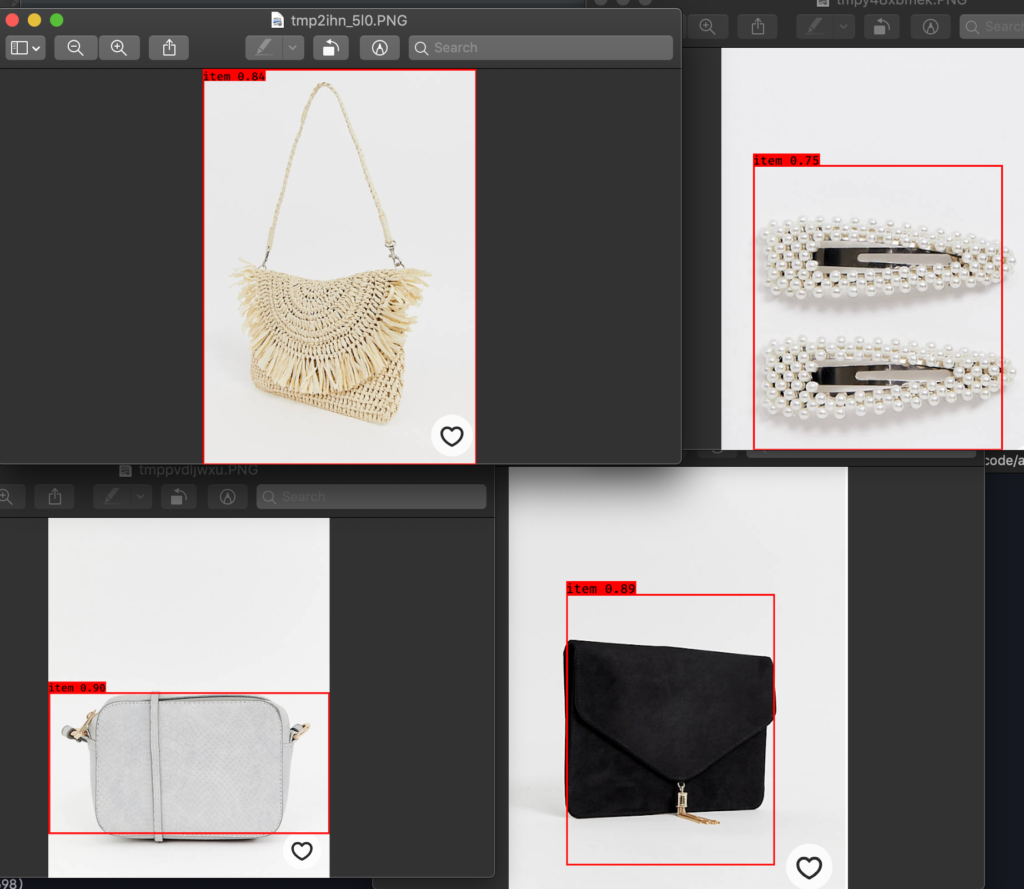
画像の場合は
python yolo_video.py --imageの後に画像のファイル名を入力でしたね。
教師データが少ないので精度は程々ですが、悪くないです。
動画の場合は
python yolo_video.py --input ファイル名.mp4でしたね。
この辺り、詳しくは前回の記事を参照してください。
まとめ:YOLOで物体検出学習させる手順
長かったですね( TДT)お疲れ様です!
うまく独自モデルの学習はできましたか?
アノテーションファイルの作成を適当にしても結構ステップがあって大変でしたよね。
もう一度、全体の流れをおさらいするとこんな感じです。
- sleepless-se/keras-yolo3 をクローン
- 教師画像をダウンロード
- 教師画像をリサイズ(python resize_images.py)
- VOTTでアノテーションを作成
- アノテーションファイルをYOLO用に変換(python voc_annotation.py)
- YOLO学習開始(python train.py)
学習させるまでのステップが多いので途中でミスってハマるポイントがいろいろありそうです。
そして、何よりCPU環境なら日が暮れて、登ってもまだ終わりません…
時々落ちるという悪夢も…(笑)
私の希望としては
「アノテーションさえしっかりやっていれば誰でも物体検出ができるよ!」
というところまで持っていきたいです。
最後に一言
この記事を書いた動機は
「物体検出が誰でもできるようになると世の中がもっと便利になる事いっぱいあるよね!」っと思ったからです。
今回のサンプルはitemでしたが対象が変わって、見る人が見ればガンの発見なんかもこれでできるようになります。
その他には
- 農作物の選果
- 万引き検知
- 防犯カメラへの応用
- 害獣の検知
- 交通調査
- 自動運転
- etc…
横展開するだけでいろんな可能性があるこの技術が
「誰でも使えて、いろんな問題に適応できて、世界がもっと便利になればいいな(๑´ڡ`๑)」
という思いです。
この記事を読んでくださった方も独自のモデルを使っていろんな問題解決にチャレンジしてみてくださいね(^^)v
今回作成したモデルはこちらの方法で簡単にAPI化してどこからでもアクセスできるようにできます。
次回は無料でGPU環境が使えるGoogleColaboを使って短時間で学習させる方法を紹介します。
今回紹介した方法がうまくいかない(>_<)!!
CPUだと遅すぎて話にならない!!
という方はこちらの方法をお試しください。


[…] 【物体検出】keras−yolo3の学習方法 […]
[…] 【物体検出】keras−yolo3の学習方法 […]
[…] 【物体検出】keras−yolo3の学習方法 […]
train.pyで独自データの学習を試みたところ、
filepath = self.filepath.format(epoch=epoch + 1, **logs)
KeyError: ‘val_loss’
とエラーが出るのですが、どこが問題なのでしょうか?
そのエラーメッセージだけでは原因を特定できませんでした。
エラーメッセージの全文をいただけますか?
同じようなエラーが発生してしまいました。
エラー全文です。
Traceback (most recent call last):
File “train.py”, line 195, in
_main()
File “train.py”, line 70, in _main
callbacks=[logging, checkpoint])
File “C:\Users\katsuno\Anaconda3\envs\py36\lib\site-packages\keras\legacy\interfaces.py”, line 91, in wrapper
return func(*args, **kwargs)
File “C:\Users\katsuno\Anaconda3\envs\py36\lib\site-packages\keras\engine\training.py”, line 1418, in fit_generator
initial_epoch=initial_epoch)
File “C:\Users\katsuno\Anaconda3\envs\py36\lib\site-packages\keras\engine\training_generator.py”, line 251, in fit_generator
callbacks.on_epoch_end(epoch, epoch_logs)
File “C:\Users\katsuno\Anaconda3\envs\py36\lib\site-packages\keras\callbacks.py”, line 79, in on_epoch_end
callback.on_epoch_end(epoch, logs)
File “C:\Users\katsuno\Anaconda3\envs\py36\lib\site-packages\keras\callbacks.py”, line 429, in on_epoch_end
filepath = self.filepath.format(epoch=epoch + 1, **logs)
KeyError: ‘val_loss’
ありがとうございます!
同じところでエラーが出ているというのはもしかするとなにか書き忘れているか間違えているかもしれませんね…
もう一度精査します。
voc_annotation.pyの6行目あたりの
classesとmodels_dataの中にある
voc_classes.txtには同じクラスが列挙されていますか?2007_test.txtに含まれるファイルが少ないことが原因でした。記事を更新しましたのでそちらをご確認ください。
train.pyの編集の際の、annotation_pathの指定先ってtrain.txtではないんですかね?
返信が遅くなり申し訳ございません(^_^;)
修正致しました!
わかりやすい記事をありがとうございます。
疑問があるのですが、
train.pyの
def _main():
annotation_path = ‘model_data/2007_test.txt’
の部分は
‘model_data/2007_train.txt’
ではないのでしょうか。
そう言っていただけて嬉しいです^^
ご指摘ありがとうございます。
凡ミス失礼致しました。修正致しました!
大変分かり易いサイトを有難うございます!以下について教えてください。
train.pyの編集の箇所でアノテーションパスにて
annotation_path = ‘model_data/2007_test.txt’となっていますが、2007_train.txtではないのでしょうか?
宜しくお願いします。
お役に立てて嬉しいです!
ご指摘ありがとうございます!
ブログ、リポジトリ修正致しました。
転移学習は可能でしょうか??
この記事は移転学習を使ったものになります。
ベースとなるモデル(ウェイト)は【学習用にweightsを変換】のところでダウンロードしています。
この記事のおかげで,学習・検出できました!
今後ですが,学習済みのモデルに新たな独自のクラスを追加し,分類できるクラス数を増やしていきたいと考えています..
そのような方法があれば教えていただきたいです.
momoさん
コメントありがとうございます!
無事に学習・検出ができると嬉しいですよね(^^)v
クラス数を増やすのであればアノテーションを付ける時にラベルの数を増やして行けば大丈夫です。
本記事と「【物体検出】アノテーションツールVoTTの使い方」を参考にすればできると思います。
webカメラを接続して、リアルタイムで実行すればどのようにコードを書き換えればいいでしょうか。
ミントさん
Webカメラの画像をPythonで読み取って処理するのはいかがでしょうか?
Webカメラからの画像の取り込みはこちらが参考になると思います。
https://stackoverflow.com/questions/604749/how-do-i-access-my-webcam-in-python
プログラミングなど全くの素人です。
でも必要と考え、色々と探して、この記事にたどり着きました。
こういうことは習うより慣れろ!と思い、詳細な理解はほとんど進んでいません。記事を読みつつコピペしてなんとか最後まで実施できたのですが、検出したい物体をうまく認識してくれませんでした。人や自動車のように「何か」を判断させたいわけではなく、単純に画像の中に「あるか、無いか」を判断させたいのです。そのような用途には不向きでしょうか?
最後の学習済みのモデルファイルの名前が、_stage_1.h5となっていました。何かが違う?なにかアドバイスを頂けたらと思いました。よろしくお願いします。
M.K.さん
プログラミングの知識無しで挑戦するのは凄いですね!
そんな方でも学習済みのファイルを作成するところまで進めるなんて私はなかなかいい記事を書きましたね。自画自賛(笑)
参照しているフォルダが違うのでしょうか?もしくは同じフォルダの中に
trained_weights_final.h5が入っているかもしれません。_stage_1.h5は名前から察するに学習途中のファイルで最後まで学習した状態ではないものだと思います。それなら「物体検出」ではなく「画像分類」をキーワードに探されたほうがピンポイントな情報が見つけられます。
ご参考になれば幸いです。
早速のお返事、ありがとうございます!
色々似たようで違う記事を見てきましたが、ご自身の関連する記事とリンクしてまとまっていて、とても良く理解を進めることができる内容でした。
参照しているフォルダなどは記事の通りなのですが・・・finalとはなっていませんでした。計算時間?も、かなり短かったと思います。アノテーションのやり方が適当はない?と推測していますが、現在確認しているケースでは何が適切なのか?も判らないので困っています。
画像分類・・・再度、探してみます。
画像処理による検出認識も(理解は進んでいませんが)確認を進めているのですが、背景が変化することなどにより適用に足らないう認識で、他の手法を探しています。このような手法の「組み合わせ」とかでもできるのか?と思っていますが、知識と理解が追いつかない(笑)
身近に相談できる人もおらず、でも時間は過ぎてゆく・・・(汗)
ありがとうございました。
私のような素人でも、これらを実行できるようにメモとして。
本日二度目の実行で気づいたことなどを、記載します。
プログラム.py内の記載はimageではなく、imagesでした。
ファイルできないなぁ?と見直して気づきました。
そして調子に乗って?Anacondaの環境をアップデートしたら、
エラーで実行できなくなってしまいました。実行環境は大切なのですねぇ。
M.K.さん
ご指摘ありがとうございます!
画像保存用のフォルダ名が間違っていました。すみません。
修正致しました。
wget が入っていないのかも知れませんね。
Macなら
brew install wgetでインストールできます。Linuxだとapt install wgetです。環境は大切ですね(^_^;)
揃えるためにもGoogleColabでGPUを使った学習方法を試されると再現しやすいと思います。
sleepless-seさん
非常にわかりやすい記事をありがとうございます。
機械学習は初めてですが、独自モデル作成し、無事に検出することができました。
恐れ入りますが、質問があるのでお答えいただけないでしょうか。
train.pyを動かした後、lossとval_lossがEpochごとに表示されますが、このlossとval_lossの目安となる数値はありますでしょうか。
私は、2回独自モデルを作成しました(計算はCPUで行なっております)。
1回目:物体Aが写っている画像100枚をアノテーションし1000Epoch実施
2回目:物体Bが写っている画像500枚をアノテーションし1000Epoch実施
それぞれ700Epochぐらいから、lossとval_lossが12〜13の間で行ったり来たりを繰り返して、1000Epochを迎えました(このモデルで検出自体は精度良くできています)。
他サイトを見ても明確にlossやval_lossの目安は書いておらず、もしよろしければ、sleepless-seさんの経験上、lossとval_lossの目安を教えていただければ幸いです。
また、12〜13程度で止まることが異常であれば、解決に向けたアドバイスをいただければありがたいです(他サイトは0.1程度のlossを表示しているものが多いのですが、私は10以下にもならず、致命的な間違いをしているのかも・・・と思っております)。
どうぞよろしくお願いします。
kageさん
コメントありがとうございます!
独自モデルの作成おめでとうございます!
lossとval_lossは普通 0~1の間の小数点で表示されます。
12~13というのは不思議な現象ですね…
不思議な値になっているようなのでプログラム側の問題だと思います。
※ 自分で動かした時の値は覚えて無くてすみません。
lossとval_lossの目安というのは無く、達成したい課題に対してどれだけ精度が出るかはケースバイケースなのでlossとval_lossの値がいくつが良いとは明言されないのだと思います。
また、アルゴリズムによって値は上下しますし、一般的にはlossとval_lossの値が小さい方が精度が良くなりますが逆のパターンも存在します。
その辺は色々やっているといずれ出会うだろうという感じです(^_^;)
ご参考になれば幸いです。
sleepless-seさん
ご返信ありがとうございます。
lossとval_lossは通常ですと0〜1なのですね・・・
別の画像で独自モデルを作成してみたのですが、lossとval_lossは5000台から徐々に下がっていき、最終的には15〜16を行ったりきたりしております。やはり1以下にならず・・・
基本的にはsleepless-seさんのプログラムに独自修正は行なっておりませんが、間違えて触ってしまった可能性も考え、再度プログラムの入れ直しを行なってみたいと思います。
lossとval_lossの目安は明言されないとのこと承知しました。
まだまだ勉強中なので、色々とパターンを試していきたいと思います。
こんにちは。わかりやすい記事をありがとうございます。
画像サイズのところで疑問があるのでコメントさせていただきます。
こちらのブログでは学習用データの画像サイズは同一にする必要があるとの記載がありますが、それはどういった理由からでしょうか?
以下のリンクでは、訓練画像のサイズを同一にする必要はないとの回答が大半を占めているように思うのですが、どちらが正しいのか判断できず困惑しております。
https://github.com/pjreddie/darknet/issues/800
やなぎさん( ◠‿◠ )トランスヒューマニズムさん
コメントありがとうございます。
お役に立てて嬉しいです(^o^)
確かに頂いたページで、「画像はどのサイズでも大丈夫」「サイズは変えないで」と書いていますね…
YOLOがというわけではないのですが、機械学習では次元数を揃えるのが基本です。次元数を揃えないと学習・予測ができません。
例えば
縦横3pxのグレースケールの画像は(縦3横3カラー1)で9次元になります。
サイズが異なる
縦横4pxのグレースケールの画像は(縦4横4カラー1)で16次元になります。
この時点で次元数が異なるので学習や予測を行う時に「次元数が一致しません」というエラーが出ます。
(Shapeが一致しません。と言われたらこのことです。)
これは機械学習である以上YOLOも同じことだと思うのですが中で何らかの操作をしているのかもしれません。
(もしわかる方がいましたらコメントを頂けると嬉しいです。)
少なくともこの記事で紹介している方法は画像サイズがバラバラだとエラーが出るはずです。
ご参考になれば幸いです。
こんばんは。
とても参考になりました。
早速で申し訳ございませんが、
学習済みモデル実行時、画像フォルダごと渡すことは可能でしょうか。
dantyさん
os.listdir()で画像フォルダーに含まれるファイル一覧を取得してfor文で回せば画像フォルダ内の画像に対して予測ができるかと思います。
ご参考になれば幸いです。
こんばんは。
お聞きしたいことがあります。
Epoch 1/50**\lib\site-packages\keras\utils\data_utils.py:718: UserWarning: An input could not be retrieved. It could be because a worker has died.We do not have any information on the lost sample.
UserWarning)
train.pyを走らせたところ学習回数までは出たのですが、その後、上記のようなUserWarningがでました。この警告は学習ができないということなのでしょうか。プログラム始めたての初心者なので当たり前のことを聞いているかもしれませんが、返信よろしくお願いしたします。
Noisaさん
質問ありがとうございます。
ログがそこで止まっているのであれば学習はできていないと思います。
学習データをどこに保存されているかわからないので参考になるか分かりませんが
こちらのページでは学習データの保存先がGoogleDriveだとダメみたいなことが書かれています。
https://www.kaggle.com/questions-and-answers/78701
環境の差異を無くすためにGoogleColabで学習する方法を試されるのも一つかと思います。
https://sleepless-se.net/2019/06/23/yolo-original-model-training-on-colab/
ご参考になれば幸いです。
こんばんは。
わかりやすい記事を拝見させていただきました。
何とか独自モデルを完成させることができ、無事物体検出を行うことができました。
一つお伺いしたいことがあります。
独自モデルでリアルタイム検出を行いたいため、動画検出のスピードを向上させたいと考えています。
そこでCPU環境だけでなく、GPUも用いて検出を行いたいのですがアドバイスいただけないでしょうか。
tensorflow-gpu,cuda,cudnn等は導入済みです。
kotokotoさん
コメントありがとうございます!
無事に独自モデルが作成できてよかったです(^^)
私は手元にGPUを使えるPCが無いので試したことがありません。
こちらの記事が参考になればいいのですが(;´∀`)
https://qiita.com/yokoponzoo/items/64137ef45208b12ce501
sleepless-seさん
とても分かりやすい記事をありがとうございます。
一つ質問があるのですが、例えばWEBカメラを用いてリアルタイムに処理をしたい場合は、yolo_video.pyのどの部分を変更すれば良いのでしょうか??
まだまだわからないことだらけで申し訳ありませんが、返信のほどよろしくお願いいたします。
oishi tomatoさん
コメントありがとうございます。
ドキュメントを見る限りでは保存された動画のみyolo_video.pyに渡せるようです。
WEBカメラからリアルタイムで物体検出をするには
WEBカメラの画像を1フレームずつ保存→1枚ずつ予測。という処理を繰り返せばできます。
こちらの方の記事で標準の学習モデルを使った方法が紹介されているので、予測の部分を作成したモデルに置き換えればやりたいことができるかと思います。
https://qiita.com/daiarg/items/a922c242af9bb76eb470
ご参考になれば幸いです。
とても分かりやすい記事で参考になりました!
ひとつ質問なのですが、こちらのプログラムでmapやlossのグラフを出力することは可能でしょうか?
ご返信よろしくお願いいたします。
hotateさん
質問ありがとうございます。
train.pyのmodel.fit_generator()のところでmAPやlossの値が返ってくると思います。
model.fit()ですが基本的にはこのやり方でグラフを作れるのではないかと思います。
https://www.codesofinterest.com/2017/03/graph-model-training-history-keras.html
未確認なので間違っていたらすみませんm(_ _)m
教えていただいた記事を参考にして何とか無事出力が行えそうです。
ありがとうございます!
どういう風に出力したか教えていただけませんか?model.fit_generator()から何とか学習曲線を取得しようとしましたがうまくできません.何かコードをついかしましたか?
はじめまして、プログラム初心者で大変参考にしながら利用させていただいています.素人でもオリジナル物体を検知できており、皆様のコメントも参考にリアルタイム動画での検知も可能になりました.ひとまず第一目標はクリアなので無事年末を越せそうなのですがいくつか質問させてください.
以前kogaさんがこちらで質問している、train.pyを動かした後のlossとval_lossの値ですが、私も10台前半を推移しています.アノテーション画像も500枚、epochも2000近く回していますが改善が見られません.そこそこ検知はできているのですが、このまま継続して2つ以上の物体検知や動線解析などに応用していきたいのですが、この手法で良いのか自信がありません.アドバイスを頂けると嬉しいです.
また、lossとval_lossだけではなく、accやval_accも表示したいのですが、他のサイトを参考にmodel.compileの中にmetrics=[‘accuracy’]を追加しましたが、常にゼロでした.上記で質問したlossとval_loss値が1以下でないことが影響していると思ったのですが、こちらもアドバイスありますでしょうか?
ちなみに、ご紹介されているgoogle colabの環境で進めています.PCが非力なので、こちらも大変参考にさせてもらいました.ご面倒おかけしますが、アドバイスいただけましたら幸いです.
m-tomiさん
コメントありがとうございます。
オリジナルで物体検出ができるようになられたみたいで大変嬉しいです。この記事を書いたかいがあります(^^)v
下手なGPU環境よりGoogleColabの方が速いのでとてもありがたいですよね。
さて、本題のlossとval_lossの値についてですがtrain.pyを読んだところ
となっており、
'yolo_loss': lambda y_true, y_pred: y_pred}の部分で表しているlossの値は実際と予想のピクセル数のズレの大きさではないかと思いました。つまり、10前後で推移しているのは予測と教師データとのズレが10ピクセル前後ということかもしれません。
詳細については分からないので、ここは本家で聞いてみるのも一つの手だと思います。
lossと同じくaccuracyを表示するには自分で実装する必要があると書いています。
確かに、何が正解か定義してあげる必要がありますね。
ご参考になれば幸いです。
非常に分かりやすい記事をありがとうございます。
Keras がつい最近大きくバージョンアップされたのを受けて、YOLO学習開始のところで
様々なエラーが出てしまいます。。
module ‘keras.backend’ has no attribute ‘control_flow_ops’
ModuleNotFoundError: No module named ‘keras.load_backend’
等のエラーですが、どのような対処が良いでしょうか?
お手数ですが、ご返信のほどよろしくお願いいたします。
ryoさん
コメントありがとうございます。
Kerasの仕様が変わっているのですね。
このkeras-yolo3の動作環境は
Python 3.5.2
Keras 2.1.5
tensorflow 1.6.0
です。すっかり書き忘れていました。記事を更新しました。
pip install -r requirements.txtでKerasとtensorflowのバージョンを揃えられます。これだけだとエラーが出る場合はPythonのバージョンも揃えてみてください。
はじめまして。
python 3.6.9
Keras 2.2.5
tensorflow 1.15.0
で、
!python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5 を実行したところ
Traceback (most recent call last):
File “convert.py”, line 262, in
_main(parser.parse_args())
File “convert.py”, line 143, in _main
buffer=weights_file.read(weights_size * 4))
TypeError: buffer is too small for requested array
と最後に表示されたのですが、できれば解決策を教えていただきたいです。よろしくお願いします。
渡邉さん
コメントありがとうございます。
返信が遅くなり申し訳ございません。
TypeError: buffer is too small for requested arrayと書いているのでColabのランタイムをすべてリセットしてからもう一度はじめからやってみるといかがでしょうか?
はじめまして。
VoTTでのExportの件なのですが、
クラスが4つ(top, right, bottom, left)矢印の方向画像(各900枚程)がありまして、
学習終了後、左矢印、右矢印の認識のみ問題がありました。1つの矢印に対しleft,right両方とも検出
されたり、左矢印の画像でrightが検出されたりなどです。上下は問題ありませんでした。
そこでVoTTで出力されたclass名_train.txt class名_val.txtを確認してみたところ
leftとrightのみ、class名_val.txtに1件も画像が設定されていませんでした。
この場合、VoTTの出力設定はどのように設定すればよろしいのでしょうか。
また、全く関係のないところで検出されたりするのですが、これは画像数を増やすしか
解決できないでしょうか。
教えていただければ幸いです。よろしくお願いします。
うるすさん
ご質問ありがとうございます。
左右の矢印を認識できていない原因はこの部分にあると思います。
ブログを書いたときからVoTTを触っていないので詳しいことはわからないのですが、
VoTTでラベル作成時に何らかの操作が原因で左右の矢印のval.txtが正しく出力されなくなってしまったのかもしれませんね。
まずは少ない画像枚数で上下左右のラベルを設定してみて正しくExportができるかを確認してみてはいかがでしょうか?
正しくExportができていれば
・大変ですがそこから900枚のラベルをつける
・おかしくなった原因を探す
のどちらかで進めると良いかと思います。
ご参考になれば幸いです。
はじめまして。大変わかりやすい記事で勉強になります。
この記事に則り、train.py を実行したところ、下記のようなエラーがでました。
anaconda3\lib\site-packages\keras\utils\data_utils.py”, line 650, in next_sample
return six.next(_SHARED_SEQUENCES[uid])
TypeError: ‘NoneType’ object is not an iterator
初心者なりに上記のエラーコードで検索をかけてみましたが、有益な情報がえられませんでした。
また、tensorflowやkerasのバージョンを色々変えてみましたが効果はありませんでした。
もし、このエラーの解決方法が分かる、もしくは、どこかエラーの原因となっていると推察されるポイントがあれば、ご教示いただけますと幸いです。
よろしくお願い致します。
Kさん
ご質問ありがとうございます。
TypeError: ‘NoneType’ object is not an iteratorと言われているのでどこかで値が
Noneで渡されているようです。エラーメッセージからはどこで発生しているものか特定できませんでした。
return six.next(_SHARED_SEQUENCES[uid])このあたりを検索したところアノテーションファイルのような事が書いてあったので、アノテーションファイルを少量で作り直してみてはいかがでしょうか?また、ローカル環境で試されているようなのでGoogleColabを使ってみると環境による違いを無くせるので良いかと思います。
ご参考になれば幸いです。
返信が遅くなり申し訳ありません。
ご指摘の通り、アノテーションをやり直したところうまくいきました。
(「python make_train_files.py」 実行時に、train.txt、test.txt、val.txtの3つファイルは作成されていたものの中味が空になっていました。)
的確なご助言ありがとうございました。
Kさん
返信ありがとうございます。
こちらこそ遅くなり申し訳ありません。
アノテーションファイルが上手く作成できていなかったのですね。
同じエラーが出た方の参考になりますね。
ありがとうございます。
はじめまして。私もプログラミング初心者ですが、
貴方様の記事のおかけでなんとかオリジナルモデルでの検出動作ができました!
が、閾値が厳しいのか検出に至りません。
yolo.pyのパラメータをいじるのだと思うのですが、どのあたりを見ればよいでしょうか?detect_imageの関数部分だとはおもうのですが…
360さん
ご質問ありがとうございます。
自信はないのですが、utils.pyの次の関数のところで
max_boxes=20が初期値として設定されているので、可能性のあるオブジェクトを確率の高い順に20個取得するのではないかと思います。https://github.com/sleepless-se/keras-yolo3/blob/master/yolo3/utils.py
なので、全く検出されないのは学習がうまくできていないのではないかと思います。
ご参考になれば幸いです。
間違っていたらすみませんm(_ _)m
はじめまして。プログラミングは全くの初心者ですが、大変わかりやすい記事でした。
一つ質問があります。学習済みデータを試してみたところ、”Found 1 boxes for img” のようにターミナル上では出力され、検出はうまくいっているようなのですが、画像が出力されません。結果画像はどこかのディレクトリに保存されるものなのでしょうか。それとも本来は画像が別窓で表示されるのでしょうか。別窓だった場合、自分の中でこれが原因ではないかと引っかかっていることは、環境がWSLだということです。
また、知識が足りず申し訳ないのですが、出力画像についてのプログラムは “yolo_video.py” の中にあるのでしょうか。環境のせいなのだとしたら、書き換えもしなければと考えています。
文章が長くなり申し訳ありません。お手隙の際にご助言を頂けたら幸いです。
0706さん
返信が遅くなりすみません。
時間が立っていて仕様を詳しく覚えていないのですが、確か入力した画像自体に線が引かれたと思います。
ご参考になれば幸いです。
非常に参考になりました。おかげで検出ができました。ありがとうございます。
100枚の画像を用いて学習モデル作成したのですが、さらに学習データなどを追加したいときはどうすればよいでしょうか??
わくわくさん
コメントありがとうございます。
更に学習したい時は100枚で学習したときと同じように画像の枚数を増やしてもう一度学習をさせ直します。
一度学習したモデルに数枚画像を足して追加で学習することができないのが機械学習の悪いところです。
そういった事ができるように日々研究されているので時間が経つと差分だけの学習も行えるようになるかもしれません。
はじめまして、初心者でも非常にわかりやすいので使わせていただいているのですが、手持ちの環境が貧弱なのでTinyモデルをトライしてみたいと考えています。
クローンしたファイルの中にはTinyでも使えそうなものがあったように思えますが(いろいろ使っているのでもしかしたら勘違いかも。。。)、コードの書き換えなどでTinyモデルでの学習、推論はできるものでしょうか?
T.Mさん
コメントありがとうございます。
Tinyモデルの使い方は「学習用にweights(重み)を変換」の見出しのところが参考になると思います。色々なモデルが公開されているので用途に合わせて使い分けられます。コードの書き換えは不要で移転学習に利用するモデルを変更するだけです。
手元のマシンが非力なのはColabを使えば解決すると思うのでこちらの記事をご参考ください。
https://sleepless-se.net/2019/06/23/yolo-original-model-training-on-colab/
はじめまして、かじりはじめた初心者です。参考にさせていただき、学習させて検出を実行したのですが何も検出されませんでした。考えられる原因はなんでしょうか。
アノテーションは800640の画像58枚の中にいるハエを1匹ずつ何匹か囲ってつくりました。
供試画像も同じく800640の画像(教師画像と似たようなもの)にして、プログラム分も該当部分を変更したつもりです。50エポック学習して、終わった時点ではlossもval_lossも100くらいの状態でした。
学習枚数が少ないのが原因でしょうか?
たぷさん
コメントありがとうございます。
画像のサイズが同じであれば問題はなさそうですし、
学習も正常にできているでのあればそれ以前のステップにも問題はないのかなと思います。
1.供試画像を変えてやってみる
2.画像の枚数を100枚くらいにしてみる
3.もう一度はじめからやり直す(教師データは使いまわし)
という順番で試してみてはいかがでしょうか?
アドバイスありがとうございます。
教師データを使いまわしてやってみたらlossもval_lossが40くらいに下がってきて、不完全ながら認識するようになりました。どうやら学習不足?だったようです。
はじめまして。大変わかりやすい記事でとても勉強になります。
質問させてください。train.pyを実行したところ「…stage_1.h5」までは生成されるのですが「…final.h5」が生成されません。どのような原因が考えられるのでしょうか。
ASHさん
コメントありがとうございます。
メモリー不足などで学習が途中で止まっているのかもしれません。
バッチサイズを小さくして実行してみるといかがでしょうか?
はじめまして.研究にYOLOを用いている大学院生です.大変分かりやすい説明なので,いつも記事を参考にさせていただいております.ありがとうございます.現在,YOLOはv4,v5と最新バージョンが次々リリースされているので,それぞれ独自モデルの学習を行いたいのですが,参考記事が少なく難儀しております.可能でありましたら,YOLOv3のように,独自モデルの学習方法を示した記事を公開して頂けると幸いです.お手数をおかけいたしますが,よろしくお願いいたします.
Remさん
コメントありがとうございます。
お役に立てて嬉しいです。
確かに既存のモデルを動かすだけの記事はいくつかありますが、自分のデータセットで学習を行う記事はあまりないようですね。
余裕があればYOLOv4,v5も記事の作成も検討させていただきますm(_ _)m
お忙しい中,ご返信ありがとうございます.
宜しくお願いいたします.