
こんばんはエンジニアの眠れない夜です。
前回はYOLOv3の独自モデルを作成しましたね。いい感じに目的のものは検出できましたか?
物体検出がうまくいったら次はそのモデルをAPI化してどこからでも画像を投げれば座標が帰ってくると嬉しいですよね。
API化されていればプロジェクトに組み込むのが簡単ですし、1度作ってしまえば別のプロジェクトでも使えますしね!
ということで、今回は前回作成したYOLOv3の独自モデルをAPI化する方法をご紹介します。
まだ、独自モデルを作成していないという方はこちらの記事を参考にしてみてください。
機械学習がずっと身近なものになりますよ!
DockerでYOLO独自モデルをAPI化
これまでにDockerを使ってAPIを作る方法を何度か紹介してきました。
今回は【Docker】2行でできる物体検出(YOLOv3)をベースにkeras−yolo3を移植したリポジトリを作りました。
keras_yolo3_object_detection_api です。
なんと長いプロジェクト名(゚∀゚)! とツッコみたくなりますがひと目見た時のわかりやすさを優先しました。
学習済みの独自モデルをAPI化する方法
下記のDockerコマンドの /path/to/yolo_weights.h5と/path/to/voc_classes.txtのパスを絶対パスで書き換えてコマンドを実行するだけです。
docker run -p 80:80 \
-v /path/to/yolo_weights.h5:/app/model_data/yolo_weights.h5 \
-v /path/to/voc_classes.txt:/app/model_data/voc_classes.txt \
registry.gitlab.com/sleepless-se/keras_yolo3_object_detection_api:latest
めっちゃ簡単ですね\(^o^)/
※ 4行で1つのコマンドです。1行にまとめても実行できます。
yolo_weights.h5は学習済みモデル(重み)です。前回の記事で作成したtrained_weights_final.h5です。
voc_classes.txtは前回作成した対象のクラスを羅列したファイルです。
【Docker】2行でできる物体検出(YOLOv3)の時もAPIの設定だけなら1行なので、タイトルが1行でも良かったんじゃないかと今になって思います。動作確認のPOSTを入れて2行です。
物体検出APIの動作確認
ここは前回と同じです。画像のパスpath/to/image.jpgを変更してPOSTするだけです。
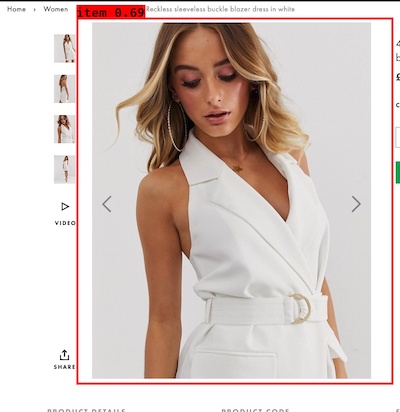
curl -X POST -F image=@path/to/image.jpg http://localhost/predictこんな感じで予測結果が帰ってくればOKです。
"[{\"box_points\": [139.98500061035156, 32.208309173583984, 720.5017700195312, 704.68017578125], \"percentage_probability\": 69.05317902565002, \"name\": \"item\"}]"
読みづらいので整形するとこうなります。
※ 出力フォーマットは【Docker】2行でできる物体検出(YOLOv3)の時と同じものにしました。
[box_points, percentage_probability, name],box_points: [139.98489379882812, 32.20841979980469, 720.5018920898438, 704.6800537109375]
percentage_probability: [69.05319094657898]
name: item
[box_points, percentage_probability, name],
…
box_points は[左、上、右、下]の座標が入っています。
(左、上)(右、下)の座標と読み替えることもできますね。
※ オリジナルのyolo.pyを使うと(下、左)(上、右)というちょっと使いづらそうな結果が帰ってきたので修正しています。
画像のサイズを320px以外で学習させた場合
今回のコンテナは320pxで学習させた場合に決め打ちであわせています。
その他のサイズで学習を行った場合はyolo.pyの29目辺りの
"model_image_size" : (320, 320),を編集してください。
APIをカスタマイズする方法
出力方法など変更したい方もいると思うので、カスタマイズ方法を紹介します。
まずはこちらからリポジトリをFolkします。
Folkしたらクローンしてください。
Docker起動時にモデルとクラスの引数を指定するのが面倒な場合はmodel_dataディレクトリにyolo_weights.h5とvoc_classes.txの名前で保存すればOKです。
※ Gitを更新する時は下記のコマンドで強制的にステージしてください。
git add -f model_data/voc_classes.txt
git add -f model_data/yolo_weights.h5出力フォーマットを変更する方法
api.pyの56行目辺りのreturn_formatを編集すればOKです。
def return_format(data):
new_data = {}
boxs = []
names = []
for box in data['box_points']:
boxs.append(,box[0],box[3],box[2]])
for name in data['name']:
names.append(classes[name])
new_data['box_points'] = boxs
new_data['percentage_probability'] = data['percentage_probability'] * 100
new_data['name'] = names
return new_datahttps://gitlab.com/sleepless-se/keras_yolo3_object_detection_apiapi.pyを編集する時はこのコマンドから実行するとnginxとuwsgi無しで、flaskに直接アクセスできます。
docker run -p 5000:5000 -v $(pwd):/app registry.gitlab.com/sleepless-se/keras_yolo3_object_detection_api python3 api.py
POSTする時はポート5000番を指定します。
http://localhost:5000
画像で確認する方法
api.pyの49行目辺りのコメントを外します。
# import cv2
# images = []
# for result in results:
# images = result['image']
# cv2.imwrite("out.jpg", np.asarray(images)[..., ::-1])
プロジェクト直下にout.jpgという最後に予測された画像が保存されます。
最後にひとこと
Docker楽ちんすぎです。
元になっているflask-uwsgi-nginxを作る時は3つのアプリケーションがどう連携するのか理解するのにすごく時間がかかりました。ですが、一度できてしまえば再利用がとても簡単です。
今回はYOLOの独自モデルをAPI化するためにkeras-yolo3をひっつけて、api.pyを編集したことによって
このブログを読んでくださっている方はモデルとクラスのパスを渡すだけでAPIを公開できるようになりました(^^)
オブジェクト指向で言うところの隠蔽化ですよね。そして、Dockerはクラスみたいなものですかね。
これで物体検出が誰でも簡単にできるようになったので
ぜひぜひ独自の物体検出モデルを使って新しいサービスを作ってみてください。
世の中が少しでも便利なることを願いします(^o^)v


[…] 【物体検出】1行で学習済みのYOLO独自モデルをAPI化する方法 […]
[…] 【物体検出】1行で学習済みのYOLO独自モデルをAPI化する方法 […]